From AI POCs to Scalable AI Solutions: Challenges and Lessons from the Trenches

Scaling an AI proof-of-concept (POC) into a full-scale production solution is far from trivial. As CTO at Imobisoft, I’ve seen firsthand how a successful demo in the lab can falter when confronted with real-world complexities. In this opinion piece, I’ll discuss the key challenges we encountered and overcame while scaling AI POCs to production. I’ll also explain why we advise clients that AI isn’t a magic fix for every problem – often the underlying data and processes need to be addressed first. The goal is to shed light on what it truly takes to move from a promising AI prototype to a robust, enterprise-ready system.
The Lure and Limitations of AI POCs
AI POCs are exciting – they offer a glimpse of what’s possible, often solving a narrowly scoped problem under controlled conditions. However, a POC is usually built quickly with minimal infrastructure. It might rely on small sample data or simplified assumptions. When transitioning to production, many limitations emerge: scalability issues, integration gaps, unpredictable model behavior, and compliance requirements, to name a few. We caution our clients early on: Don’t pursue AI just for the sake of AI. Any AI initiative must serve a clear business purpose; otherwise it’s easy to “add AI” to processes without actual impact. In fact, one of the first questions we tackle is: What business problem are we trying to solve, and is AI the best solution? This ensures we avoid the trap of using AI as a shiny hammer for every nail.
Equally important is managing expectations. A flashy demo might impress stakeholders, but a production system faces scrutiny on reliability, accuracy, and ROI. Business leaders and technical teams both need to align on what success looks like beyond the POC. Is the goal to automate a workflow, augment decision-making, or reduce costs? Clarity here dictates the design and metrics of the eventual solution. We’ve learned to bridge the gap between business objectives and technical feasibility early – a theme I’ll return to later.

Laying the Foundations: Data Readiness Before AI
One hard truth in AI deployment is: “AI is only as good as the data it learns from.” No algorithm can overcome fundamentally bad or insufficient data. In our experience, many organizations discover during the POC phase that their data is siloed, inconsistent, or of poor quality. We often need to pause and help clients fix these foundational issues before an AI solution will yield meaningful results. This involves assessing data maturity and quality – essentially a health check of the company’s information assets. We ask questions like: What data do you actually have? How clean and complete is it? Where are the gaps or privacy risks? A robust data maturity assessment looks at all these aspects.
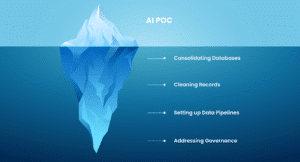
If the data isn’t up to par, the first step might not even be building an AI model at all, but rather data engineering: consolidating databases, cleaning records, setting up data pipelines, and addressing governance. We’ve had projects where simply integrating different data sources or correcting data quality issues delivered huge business value before any AI was added. By investing in a strong data foundation, we ensure that when we do deploy machine learning or an LLM, it has reliable fuel to learn from. This foundation-building mindset is something we emphasize to both technical teams and business heads – it might extend timelines initially, but it de-risks the final outcome.
Finally, focusing on data readiness helps set realistic expectations. It sends a message that AI isn’t a plug-and-play fix for systemic data problems. Clients appreciate when we’re candid that certain issues must be solved the “old-fashioned” way (through better processes or data management) before an AI can effectively help. This honesty ultimately saves time and budget, steering organizations away from trying to solve everything with AI and instead applying it where it truly makes a difference.
Ensuring Consistency and Reliability in AI Outputs
One major challenge we faced in scaling up AI solutions is the consistency and accuracy of Large Language Model (LLM) outputs. Off-the-shelf LLMs can be remarkably powerful, but they are also stochastic by nature – the same prompt might yield different answers on different runs, and they are prone to “hallucinations” (confidently stating incorrect information). In a controlled POC, a few hallucinations or inconsistent answers might be tolerated, but in production – especially in high-stakes domains – this is unacceptable. Our clients (rightfully) expect reliable, factual, and repeatable results.
To tackle this, we employ several strategies. A key approach is Retrieval-Augmented Generation (RAG), which grounds the LLM with real, context-specific data. In essence, we feed the model with relevant supporting documents from a vetted knowledge base before it generates an answer. This significantly improves factual accuracy. By augmenting the model with up-to-date, domain-specific information, we mitigate knowledge gaps and reduce the chance it will invent facts. RAG has the added benefit that we don’t need to retrain a large model for every new knowledge domain – instead, we let it retrieve the latest information as needed.
Another tactic is implementing additional filtering and verification layers on top of the LLM’s output. For example, in one project we introduced a secondary validation step: after the primary model produced an answer, a “verifier” agent (or set of rules) would cross-check that answer against trusted sources and business rules. This could catch obvious errors or policy violations before the result ever reached the end-user. In our pharmaceutical compliance solution (discussed below), we even designed an agent whose sole job was to review the main AI’s findings to ensure they were evidence-backed and free of hallucinations. Likewise, we incorporate guardrails directly into our prompts and system design – instructing our models not to speculate or produce information unless it’s validated by a source. In fact, our compliance AI’s guidelines explicitly state: “Do not hallucinate… or return any knowledge without first validating with tools.”. By baking such rules into the system (and leveraging tools like OpenAI’s function calling or chain-of-thought prompting), we greatly improve consistency.
Finally, achieving reliability at scale involves rigorous testing and monitoring. Before deployment, we test AI components under a variety of scenarios – not just the happy path from the POC demo. We evaluate how the system handles edge cases, noisy inputs, or ambiguous queries. We also use techniques like ensemble checks or consensus (having the model generate multiple attempts and checking for consistency among answers) when feasible. In production, continuous monitoring is set up to detect drifts in model performance or unusual outputs, so we can intervene early. This engineering work – logging every AI decision, tracking accuracy metrics, setting up alerts – is crucial for building trust in the solution over time. It’s not as glamorous as the AI model itself, but it’s part of making the solution truly enterprise-grade.

Bridging Business and Technical Perspectives
Throughout the journey from POC to production, one lesson stands out: success requires tight collaboration between the business and technical teams – essentially a bridge between the business heads and the technical heads. As a CTO, I often find myself translating between these worlds. The technical team needs to understand the real-world requirements and constraints (for instance, what level of accuracy is truly needed, how the end-users will use the AI tool, what regulatory constraints exist). Meanwhile, the business team needs to grasp the technological possibilities and limitations (for example, an AI’s output might need post-processing, or why certain features take longer to implement for reliability).
In scaling our AI projects, we made sure to involve stakeholders from both sides early and often. In the pharma compliance project, we worked closely with compliance officers (business/domain experts) to define what a “good” result looks like and what risks had to be mitigated. Their input guided our priorities – for instance, the requirement for evidence in outputs came straight from business needs. Conversely, we educated the business stakeholders on why the AI might need to occasionally defer to human judgment or why it needed access to certain data. This two-way education builds trust on both sides. Business leaders become more realistic about AI (seeing it as a tool that augments humans, not a sci-fi oracle), and technical teams become more tuing and feedback loops) are essential. By highlighting these aspects, business sponsors understand that an AI project is not just a software install, but an evolving capability that needs care and feeding. The reward, of course, is that when done right, AI can become a competitive advantage – delivering continuous value and learning over time.
Lastly, having cross-functional teams has been a game-changer. We pair data scientists and ML engineers with industry SMEs, software developers, and UX designers. This ensures that the AI solution is not built in a silo. It’s integrated with the company’s IT stack (e.g. connecting to CRM or ERP systems where needed), and it’s designed with the end-user’s workflow in mind. In production deployments, we’ve integrated AI outputs into familiar tools (like showing compliance flags in a content management system) rather than expecting users to adopt an entirely new interface. These integration efforts and user experience considerations are often overlooked in a POC, but they determine whether the solution is actually adopted at scale. In short, scaling AI is as much about change management and design as it is about algorithms.ned into delivering business value rather than just cool tech.
From an organizational standpoint, scaling AI solutions often requires new processes that blend into existing operations. We’ve had to implement MLOps practices – version-controlled model pipelines, continuous monitoring of model performance, regular updates – and explain their importance to non-technical executives. For example, deploying an AI model isn’t a one-off victory; it’s the start of an ongoing cycle of maintenance and improvement. We set expectations that models may need retraining with new data, metrics must be tracked and reported, and support processes (like user train
Conclusion
Transitioning from an AI POC to a full-scale production solution is a journey filled with challenges – from technical hurdles like LLM consistency and data quality to organizational hurdles like aligning stakeholders and ensuring user adoption. The experiences at Imobisoft have taught us that success comes from addressing all these facets holistically. We’ve learned to be skeptical of the hype and focus on fundamentals: get the data right, choose the right tool for the job (even if sometimes the right tool isn’t AI at all), enforce reliability and accuracy through engineering rigor, and always tie the solution back to real business needs.
For companies looking to scale their AI initiatives, my advice is to plan beyond the prototype. Think about the end-to-end system: how will it ingest data, how will it make decisions transparently, how will it integrate with existing systems, how will you maintain it, and how will people actually use it day-to-day? By anticipating these questions early, you can design your POC in a way that naturally extends to production rather than hitting a dead-end. And remember that success requires collaboration – your AI team, IT team, and business units should work in unison, much like an orchestra, to turn a promising AI model into a transformative business solution.
In the end, the true measure of an AI solution’s success is not whether it wowed people in a demo, but whether it delivers consistent, reliable value at scale. Achieving that is certainly challenging, but with the right approach and mindset, it’s absolutely attainable – we’ve seen it in our projects. As a CTO, witnessing an AI solution we nurtured from concept to deployment creating real impact is immensely rewarding. It reinforces our belief that AI’s real power is unleashed not in isolated experiments, but in carefully crafted implementations that solve real problems, day after day, in the messy complexity of the real world.